Mục lục
Mục đích:
Chủ đề của bài này giới thiệu XPath, một thành phần hỗ trợ giúp truy xuất thông tin trong tập tin XML làm tiền đề cho việc áp dụng stylesheet kết hợp XML để tạo ra kết xuất tùy theo yêu cầu. Bên cạnh đó XPath cũng làm nền tảng cho việc hỗ trợ truy vấn parsing dữ liệu của tài liệu XML cực kỳ nhanh chóng hiệu quả. Hơn thế nữa, XPath hỗ trợ nền tảng để tạo ra XQuery áp dụng trong truy vấn dữ liệu tương tự như truy vấn SQL trên cơ sở dữ liệu

Yêu cầu về kiến thức cơ bản
- Nắm vững các khái niệm về XML và cách viết tài liệu XML well-formed (tham khảo lại bài Giới thiệu về XML – định nghĩa, cách viết XML đúng cú pháp (XML well-formed) )
- Nắm vững các khái niệm về namespace và cách sử dụng namespace trong tài liệu XML (tham khảo lại bài Sử dụng XML với namespace – Sử dụng kết hợp những tài liệu XML với nhau từ nhiều người định nghĩa khác nhau)
- Nắm vững khái niệm về ngôn ngữ lập trình PHP, lập trình thao tác hướng đối tượng, sử dụng các method hay function
- Đã viết và kiểm tra một tài liệu XML well-formed
- Nắm vững và đã sử dụng tốt ngôn ngữ truy vấn SQL trên các trình quản lý cơ sở dữ liệu quan hệ
Tổng quan XPath
-
Định nghĩa :
- Xpath là một trong ba thành phần trong ngôn ngữ XSL – Extensible Style Language
- Là ngôn ngữ hỗ trợ tìm kiếm thông tin trong tài liệu XML qua việc sử dụng biểu thức XPath để định hướng tìm kiếm dữ liệu trên XML thay vì phải thực hiện tìm kiếm đệ qui để duyệt cây XML
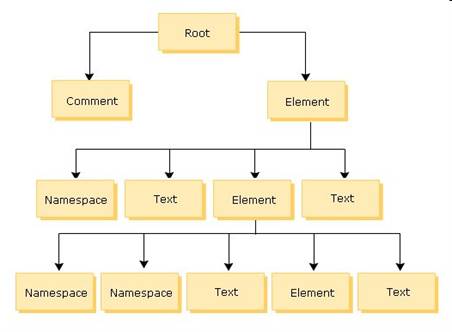
- Xpath định nghĩa 7 loại nodes theo mô hình thể hiện bên dưới từ root, element, attribute, text, namespace, processing-instruction và comment tương tự như khái niệm về cấu trúc tài liệu XML mà chúng tôi đã giới thiệu trong bài Giới thiệu về XML – định nghĩa, cách viết XML đúng cú pháp (XML well-formed)
-
- Ngoài ra, Xpath còn định nghĩa một số node đặc biệt để thể hiện mối quan hệ giữa các node trong mô hình trong quá trình xử lý như sau
- Parent Node: node trên trực tiếp của node hiện hành
- Child Node: tập node trực tiếp của node hiện hành cấp thấp hơn
- Sibling: node ngang hàng hay cùng cha với node hiện hành
- Ancestors: tất cả node con bên trên node hiện hành cùng nhánh
- Descendants: tất cả node con bên dưới của node hiện hành cùng nhánh
- Ngoài ra, Xpath còn định nghĩa một số node đặc biệt để thể hiện mối quan hệ giữa các node trong mô hình trong quá trình xử lý như sau
-
Xpath Data Model
- Được định nghĩa là duyệt toàn bộ cây nội dung XML và chuyển đổi – mapping chúng thành 7 loại node đã mô tả ở trên và XPath thực hiện truy vấn trên nội dung cây XML đã được tạo ra.
- Mỗi node trong XPath đều có giá trị kiểu chuỗi chứa thông tin của một node bao gồm localname và namespace nếu có để có thể truy vấn đến node trong mô hình một cách dễ dàng thông qua tên
-
Cú pháp của XPath
- Để truy vấn với đường dẫn tuyệt đối nghĩa là đi từ root của tài liệu XML đến các thành phần cần truy cập, XPath qui định với cú pháp bắt đầu bằng dấu /
- Để truy vấn với đường dận tương đối để có thể truy cập đến thành phần bất kỳ thỏa điều kiện, XPath qui định cú pháp sử dụng với dấu //
- Để truy vấn đến một thành phần bất kỳ mà không cần biết tên của nó là gì, XPath qui định ký tự sử dụng là *
- Để truy cập thuộc tính của một node, XPath qui định thuộc tính truy vấn phải có cú pháp bắt đầu là @. Ví dụ @tênThuộcTính
- Để truy cập đến giá trị của một biến được định nghĩa, XPath qui định biến truy vấn phải có cú pháp bắt đầu là $. Ví dụ $tênBiến
- Điều kiện khi truy vấn được đặt trong dấu []
- Truy vấn lựa chọn nodes
| Biểu thức | Định nghĩa |
| tênNode | Chọn tất cả các node con của tênNode |
| / | Chọn tất cả các node tính từ root |
| // | Chọn tất cả node tính từ node hiện hành |
| . | Chọn node hiện hành |
| .. | Chọn node cha của node hiện hành |
-
Các phép toán được sử dụng trong XPath
- Đại số: +, -, * (nhân), div (chia thập phân), mod (chia lấy dư)
- So Sánh hay quan hệ: =, != (khác), <, <=, >, >=
- Luận lý: true, false, and, or, not
- Kết hợp: | (hội)
-
Các thành phần hỗ trợ truy vấn mối quan hệ giữa các node trong tài liệu XML (Axes)
- Cú pháp: TênAxis::tênNode
| Axis | Định nghĩa |
| ancestor | Chọn tất cả các node trên của node hiện hành |
| ancestor-or-self | Chọn tất cả các node trên của node hiện hành và chính nó |
| attribute | Chọn tất cả các thuộc tính của node hiện hành |
| child | Chọn node con của node hiện hành |
| descendant | Chọn tất cả các node dưới của node hiện hành |
| descendant-or-self | Chọn tất cả các node dưới của node hiện hành và chính nó |
| following | Chọn tất cả các node sau khi tag đóng của node hiện hành |
| following-sibling | Chọn tất cả các node ngang cấp sau khi tag đóng của node hiện hành |
| namespace | Chọn tất cả namespace của node hiện hành |
| parent | Chọn tất cả node cha của node hiện hành |
| preceding | Chọn tất cả các thành phần trước khi bắt đầu tag mở của node hiện hành |
| preceding-sibling | Chọn tất cả các node ngang hàng trước khi bắt đầu tag mở của node hiện hành |
| self | Chọn node hiện hành |
-
Các functions trong XPath
| Hàm | Định nghĩa |
| node-name(node) | Trả về tên node của node được đưa vào hàm |
| nilled(node) | Trả về true nếu node là null |
| data(item, item, …) | Lấy các trị tuần tự của các items đưa vào |
| base-uri() | Lấy trị thuộc tính base-uri của node hiện hành |
| base-uri(node) | Lấy trị của thuộc tính base-uri của node |
| document-uri() | Lấy trị của thuộc tính document-uri của tài liệu XML |
| number(arg) | Trả về kiểu số |
| abs(num) | Lấy trị tuyệt đối |
| ceiling(num) | Lấy trị số nguyên nhỏ nhất lớn hơn num |
| floor(num) | Lấy trị số nguyên lớn nhất nhỏ hơn num |
| string(arg) | Trả về kiểu chuỗi |
| compare(comp1, comp2) | So sánh giá trị cho comp1 với comp2, -1 là nhỏ hơn, 0 là bằng nhau và 1 là lớn hơn |
| concat(string, string, …) | Nối chuỗi |
| substring(string, start [,len]) | Lấy chuỗi con trong string đưa vào |
| string-length([string]) | Lấy chiều dài của string node hiện hành hay từ string |
| normalize-space([string]) | Loại bỏ ký tự khoảng trắng thừa trong và ngoài chuỗi string của node hiện hành hay string |
| normalize-unicode | Tương tự như normalize-space nhưng dùng cho Unicode |
| translate(string1, string2, string3) | Convert chuỗi string1 bằng cách thay thế chuỗi string3 thay thế chuỗi string 2 |
| contains(string1, string2) | Trả ra true nếu string1 chứa string2 |
| match(string1, pattern) | Trả ra true nếu string1 tuân thủ đúng pattern |
| replace(string1, pattern, replace) | Thay thế chuỗi replace với thành phần trong string1 đúng pattern |
| tokenize(string, pattern) | Tương tự hàm split của ngôn ngữ java |
| boolean(arg) | Convert giá trị arg trở về kiểu luận lý true hay false |
| count([node]) | Trả về số lượng node của node |
| last() | Trả về node cuối cùng trong node hiện hành |
| local-name([node]) | Trả về tên node nằm sau phần dấu : |
| name() | Trả về namespace qualified prefix:tênNode |
| namespace-uri([node]) | Trả về uri của namespace của node hiện hành hay node |
| text() | Trả về chuỗi trị của node |
| position() | Trả về vị trí của node |
Chúng ta đã hoàn tất lý thuyết cơ bản của Xpath.
Vận dụng các kiến thức về Schema ở trên để áp dụng truy vấn tài liệu XML sử dụng XPath để hiểu rõ XPath và áp dụng cho các chủ đề tiếp theo về áp dụng stylesheet và parsing tài liệu XML thông qua một số ví dụ cụ thể về truy vấn Xpath bên dưới
- Yêu cầu
- Nắm vững các khái niệm về XML (tham khảo lại bài Giới thiệu về XML – định nghĩa, cách viết XML đúng cú pháp (XML well-formed))
- Nắm vững các khái niệm về namespace và cách sử dụng namespace trong tài liệu XML (tham khảo lại bài Sử dụng XML với namespace – Sử dụng kết hợp những tài liệu XML với nhau từ nhiều người định nghĩa khác nhau)
- Nắm vững các khái niệm về Xpath đã nêu ở trên
- Tools sử dụng ở đây là Netbeans 6.9.1
- JDK 6 update 22
- Các bước thực hiện
- Add plugin hỗ trợ kiểm tra biễu thức XPath vào Netbeans 6.9.1
- Download gói plugin Xpath tại đây với tên org-sougata-util-nb-xpathev_6.9.1.0.nbm. Tập tin có đuôi .nbm
- Di chuyển đến thư mục
- Windows XP: C:\Documents and Settings\[Tên account login vào windows]\.netbeans\6.9
- Windows Vista, 7: C:\Users\[Tên account login vào windows]\.netbeans\6.9
- Tạo thư mục update
- Vào thư mục update, tạo thư mục download
- Chép tập tin download ở trên vào trong thư mục download.
- Mở lại Netbeans 6.9.1, màn hình update sẽ xuất hiện, sau đó netbeans được khởi động như bình thường (tập tin nbm trong thư mục download sẽ biến mất)
- Màn hình netbeans với việc cập thành công thể hiện như sau
- Add plugin hỗ trợ kiểm tra biễu thức XPath vào Netbeans 6.9.1

- Click vào Xpath, cửa số Xpath sẽ mở ra

-
- Xpath: nhập chuỗi Xpath để testing
- Resolve namespace automatically: dùng áp dụng cho tài liệu có sử dụng namespace
- Return As: để chọn kết quả truy vấn trả về
- Node: lấy một node đầu tiên duy nhất
- NodeList: tập các node
- String: value của node đầu tiên được truy vấn
- Number: trả về kiểu số trị của node đầu tiên được truy vấn
- Boolean: trả về truy vấn true nếu có node
- Nút Evaluate: nhấn để thực hiện truy vấn
- Chú ý:
- Tài liệu XML phải được chọn trước hay mở trước, sau đó mới mở cửa số XPath thì mới thực hiện truy vấn được
- Nếu mở tài liệu không phải XML hay chọn tài liệu khác trước khi chọn cửa số XPath, thì ngay tại dòng evaluate sẽ báo lỗi
- Thực hiện ví dụ để tìm hiểu rõ định nghĩa về XPath
- Chúng tôi sẽ sử dụng tài liệu XML đầu tiên không có namespace để thực hiện truy vấn từ cơ bản đển nâng cao
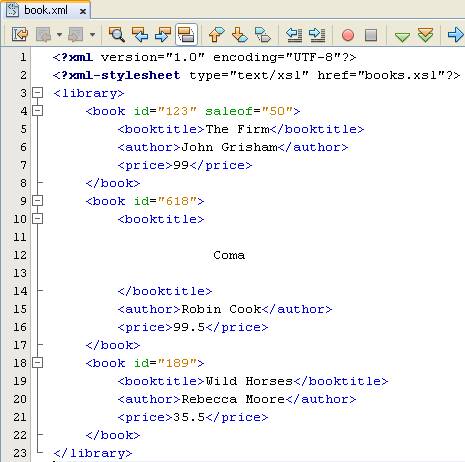
- Chúng ta thực hiện truy vấn đầu tiên với chỉ dấu /

-
- Chúng ta có toàn bộ tài liệu XML với dấu /
- Chúng ta thực hiện truy vấn lấy tất cả quyển sách của thư viện
- Chúng ta nhận thấy rằng book nằm trong library, và library nằm dưới root do vậy truy vấn của chúng ta như sau

-
- Kết quả chúng ta sẽ có tất cả các node book
- Tương tự như thế, chúng ta truy vấn tất cả tên tác giả trong thư viện
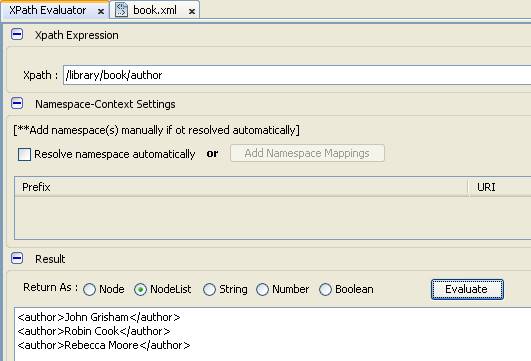
- Chúng ta thực hiện truy vấn trực tiếp author mà không cần thông qua library và book như truy vấn bên dưới có được không?
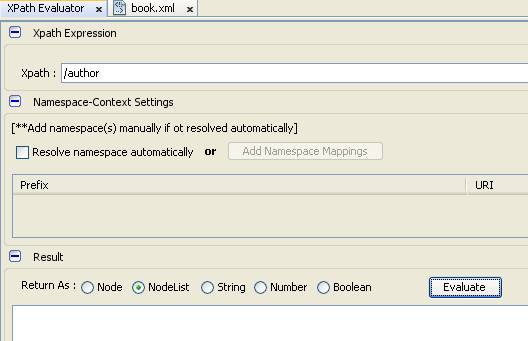
- Chúng ta nhận được kết quả trắng vì từ root đi ra không có node nào tên author nên kết quả tìm kiếm là không tìm thấy
- Để hạn chế việc sử dụng đường dẫn tuyệt đối và viết quá dài dòng, chúng ta áp dụng đường dẫn tương đối như trong lý thuyết thay thế như sau
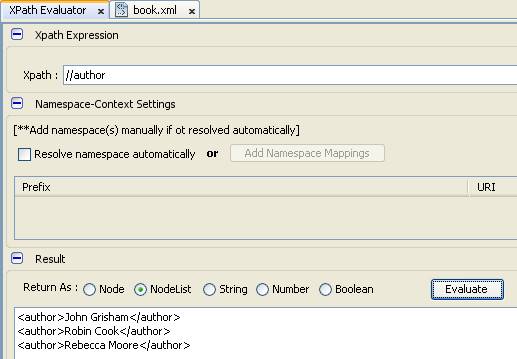
- Chúng ta có kết quả tương tự
- Lưu ý
- Khi chúng ta dùng / thì được nhưng dùng // không sẽ có lỗi xảy ra vì tương đối là phải chỉ định, không cho phép tùy ý
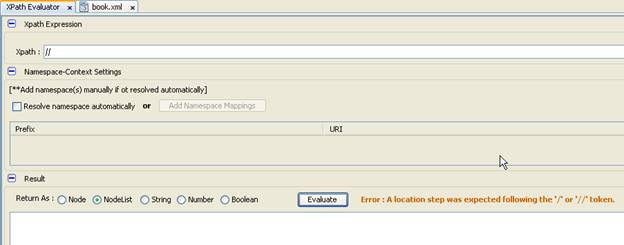
- Khi chọn tài liệu khác XML trước khi chọn XPath, cho dù trên cửa số có XML di nữa chúng ta sẽ nhận lỗi như sau

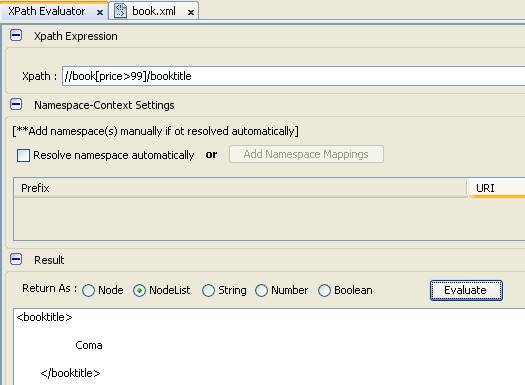
- Chúng ta thực hiện truy vấn với điều kiện “tìm tất cả tên quyển sách có giá lớn hơn 99”
- Chúng ta dùng đường dẫn tương đối và phân tích.
- Đầu tiên chúng ta cần có sách, vì có sách mới tính đến giá vì giá là node con trong sách
- Sau đó, có sách thỏa điều kiện thì chúng ta mới lọc ra tên
- Câu lệnh truy vấn của chúng ta như sau
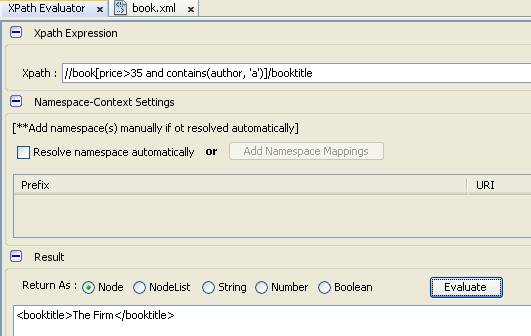
- Chúng ta thực hiện ví dụ kết hợp hàm biểu thức với điều kiện “tìm tất cả quyển sách lớn hơn 30 đồng và tên tác giả có chứa chữ a”
- Chúng ta sẽ kết hợp hàm và hàm chọn lựa là hàm contains để tìm chữ có chứa trong chuỗi khác hay không
- Câu lệnh truy vấn của chúng ta
-
- Trong chuỗi truy vấn trên cần lưu ý việc sử dụng chuỗi phải dùng dấu ‘’ hay “” để bao trị, nếu không thôi XPath sẽ coi tên như là node để tìm kiếm trong XML
- Truy vấn tên tác giả có tựa sách là Coma
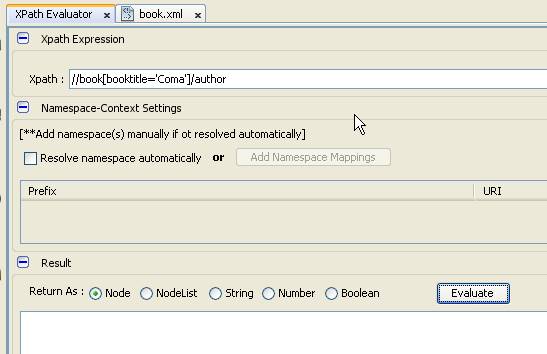
- Chúng ta không nhận được kết quả vì Coma đang tìm chính xác nhưng tài liệu XML chúng ta có chứa ký tự xuống dòng và tab, do vậy, chúng ta cần chuẩn hóa chuỗi loại bỏ khoảng trắng trước khi tìm kiếm với hàm normalize-space
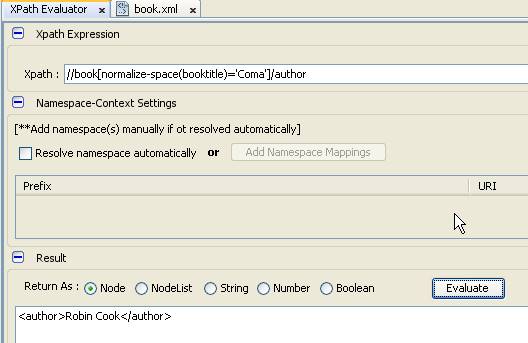
- Cũng với điều kiện trên nhưng chúng ta chỉ cần giá trị text không phải là một node, chúng ta kết hợp hàm trong truy vấn như sau

- Truy vấn quyển sách đứng thứ nhất trong kết quả trả về
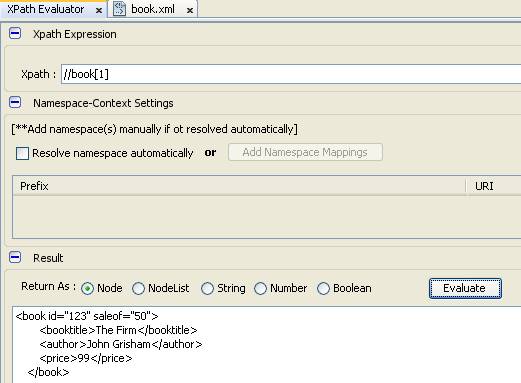
- Truy vấn quyển sách cuối cùng trong kết quả truy vấn
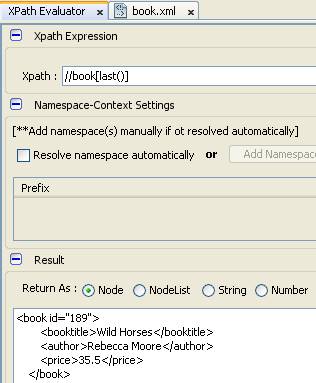
- Truy vấn quyển sách ở vị trí thứ 2 trong kết quả trả về
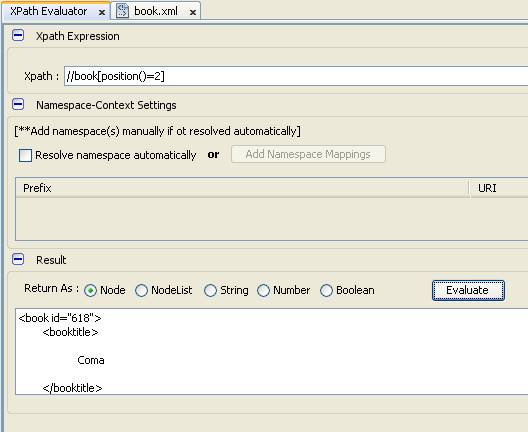
-
- Chúng ta có thể áp dụng phép toán so sánh với >, <, … ở đây để điều kiện trở nên linh hoạt
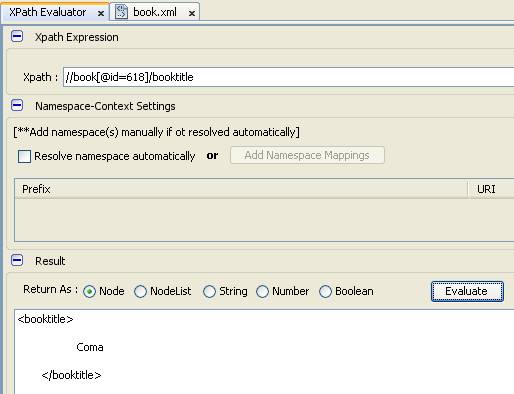
- Tìm tựa quyển sách có id là 618
- Chúng ta áp dụng truy vấn với thuộc tính id và dùng dấu @ trong mệnh đề điều kiện
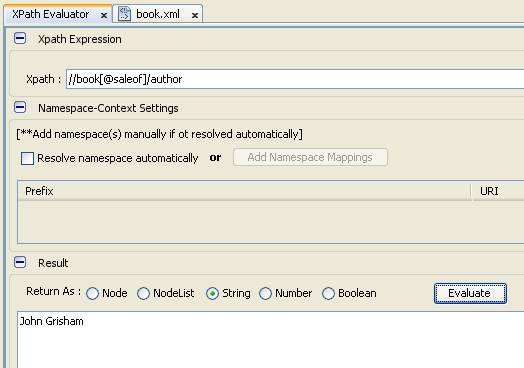
- Tìm tên tác giả của các quyển sách có thuộc tính saleof
- Ở đây chúng ta không quan tâm trị mà quan tâm node nào có chứa thuộc tính, do vậy, chỉ cần ghi thuộc tính là đủ
- Chúng ta sẽ thực hiện truy vấn trên tài liệu có namespace như sau
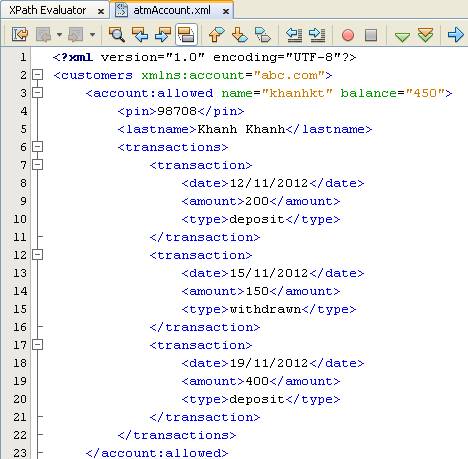


- Chúng ta thực hiện truy vấn tìm kiếm các lastname của các account còn sử dụng được
- Câu lệnh truy vấn của chúng ta như sau
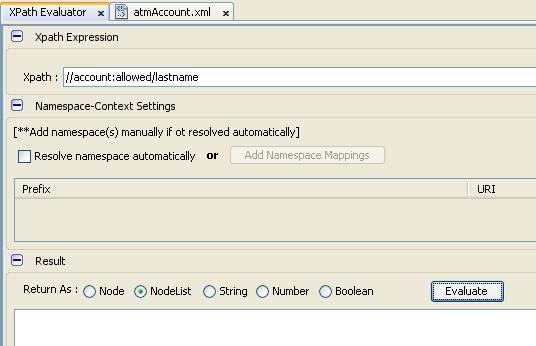
- Chúng ta không thể truy vấn được vì XPath không hiểu namespace được định nghĩa trong tài liệu XML, do vậy truy vấn sẽ không tìm thấy node tên account:allowed vì nó coi : là một tên
- Để khắc phục chúng ta thực hiện 02 cách với các ưu khuyết để chúng ta lựa chọn
- Cách 1: check bật Resolve namespace automatically
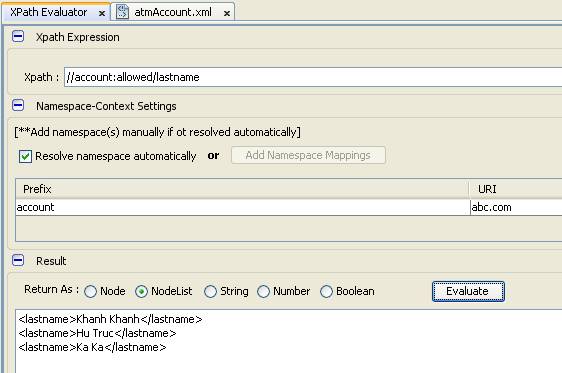
- Chúng ta có kết quả đúng nhưng lệ thuộc vào việc thông báo XPath. Câu hỏi đặt ra, chúng ta muốn nó uyển chuyển không lệ thuộc và chạy tất cả trên mọi ứng dụng thì chúng ta sẽ kết hợp hàm cùng một số phép toán và ký tự đặc biệt theo cách thứ 2
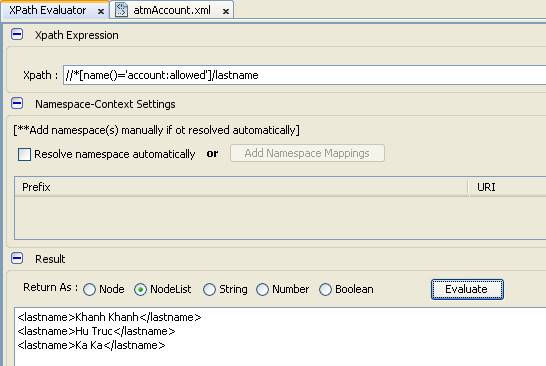
- Kết quả ra tương tự và có nhiều ưu điểm hơn
- Chúng ta có thể áp dụng tương tự với hàm local-name như sau
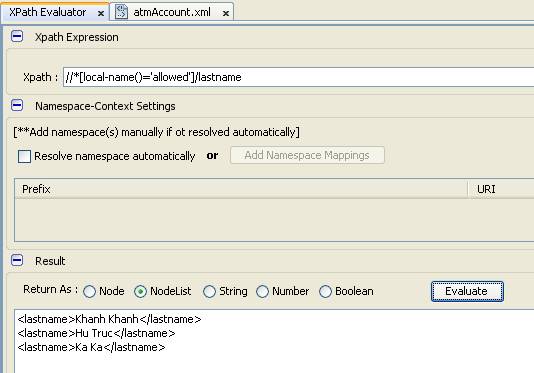
- Tìm tất cả name của các account không phân biệt là expired hay allowed nhưng có balance lớn hơn 40, trong tên có chứa chữ u
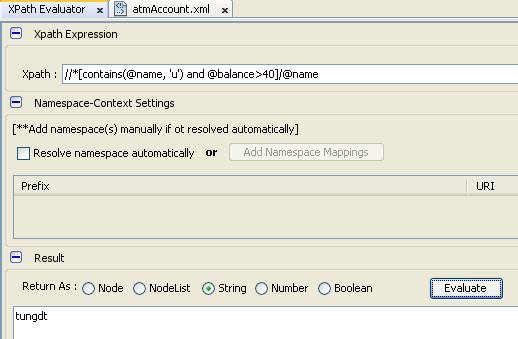
- Name là một attribute, do vậy, khi sử dụng chúng ta phải dùng @
- Chúng ta có thể thực hiện cách tương tự dùng axis
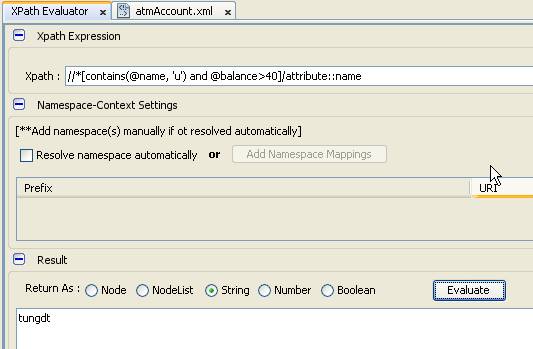
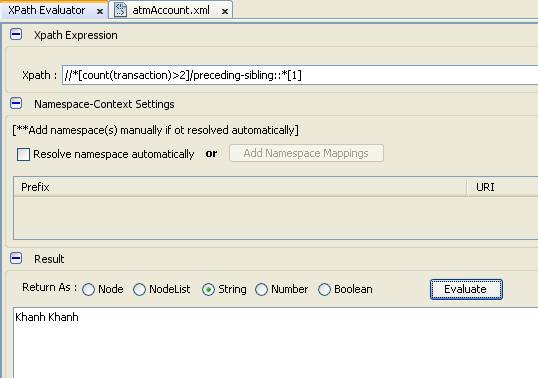
- Tìm kiếm tất cả các lastname của các account có số lần giao dịch nhiều hơn 02 lần
- Chúng ta áp dụng hàm count để đếm số transaction lớn hơn 2. Tuy nhiên hàm count sẽ trả về node bắt đầu đếm là transactions
- Do vậy, chúng ta phải tìm node anh em trước nó sử dụng axis
- Sau đó, tìm anh em kế cận nó là lastname
- Câu truy vấn như sau
- Trên đây chỉ là một số ví dụ tổng quan đến chúng ta tiếp cận nội dung XPath và các thức truy vấn tài liệu XML. Quí vị cần tự nâng cao kiến thức của mình về XPath bằng cách tự đặt câu truy vấn và thực hiện
Chúc mừng các bạn đã hoàn tất và nắm các khái niệm về sử dụng Xpath và ứng dụng nó trong truy vấn tài liệu XML. Chúng ta sẽ áp dụng nó trong các nội dung tiếp theo của chủ đề liên quan đến khái niệm và sử dụng stylesheet cũng như chuyển đổi định dạng tài liệu sang PDF
Rất mong sự góp ý chân thành và chia sẻ của quí vị về vấn đề này. Hẹn gặp lại quý vị ở các chủ đề liên quan đến XML, cụ thể sẽ là vấn đề liên quan đến việc xây dựng XSL – Extensible Style Language để áp dụng truy vấn, lọc và chuyển đổi tài liệu XML.
Nguồn : kieutrongkhanh.net
Bài viết liên quan
 Tổng quan về XML DOM
Tổng quan về XML DOM Giới thiệu về XML – định nghĩa, cách viết XML đúng cú pháp (XML well-formed)
Giới thiệu về XML – định nghĩa, cách viết XML đúng cú pháp (XML well-formed) Những khái niệm cơ bản về DOM
Những khái niệm cơ bản về DOM Compare Redis and Memcached – So sánh Redis và Memcached
Compare Redis and Memcached – So sánh Redis và Memcached Sử dụng XML với namespace – Sử dụng kết hợp những tài liệu XML với nhau từ nhiều người định nghĩa khác nhau
Sử dụng XML với namespace – Sử dụng kết hợp những tài liệu XML với nhau từ nhiều người định nghĩa khác nhau Free up ram Centos / Redhat – Giải phóng RAM Centos
Free up ram Centos / Redhat – Giải phóng RAM Centos Inglourious Basterds – 2009 (Định Mệnh)
Inglourious Basterds – 2009 (Định Mệnh) Hướng dẫn cài đặt Xdebug cho PHP trên Centos
Hướng dẫn cài đặt Xdebug cho PHP trên Centos